awesome-japanese-llm
Overview of Japanese LLMs
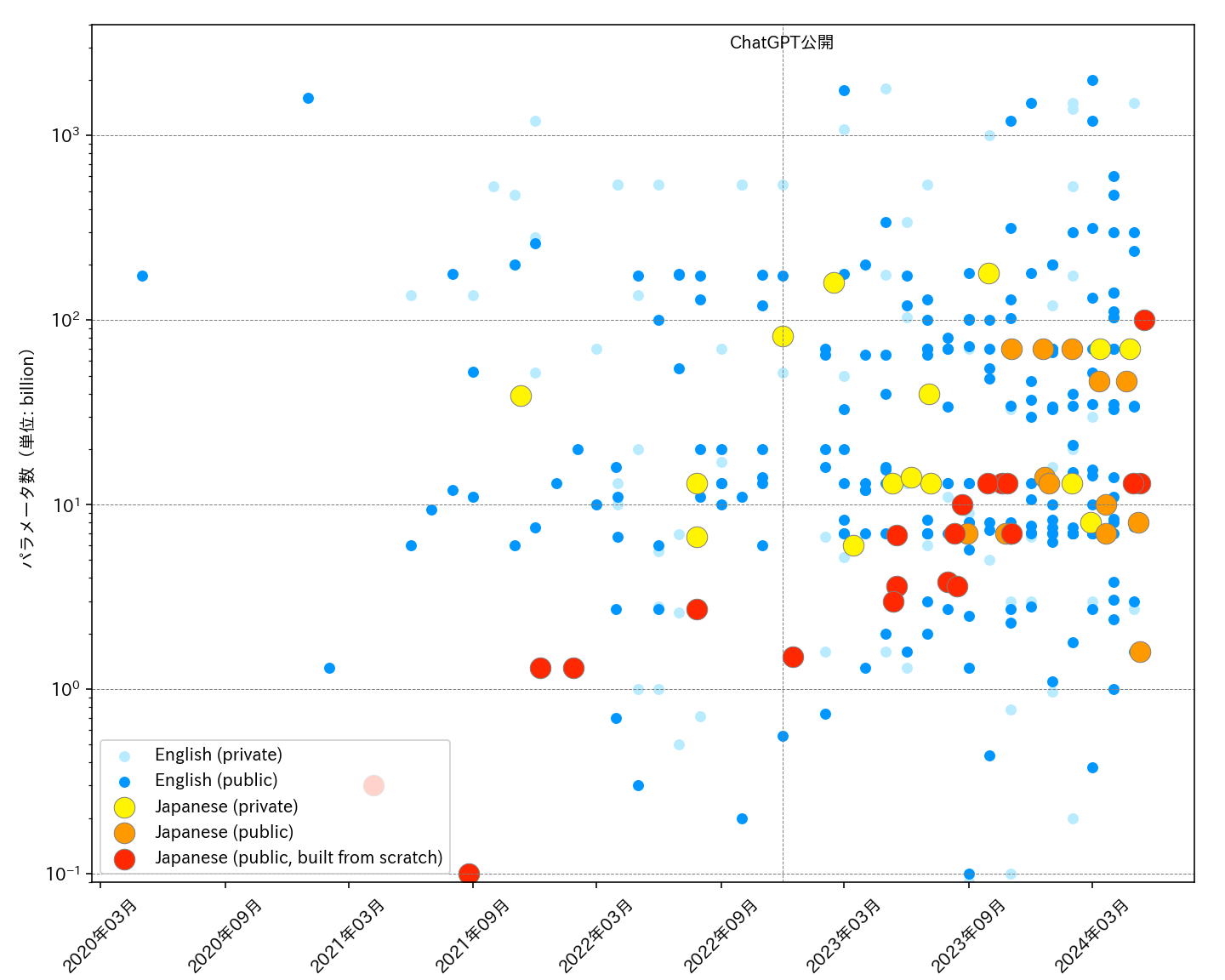
A list of publicly available LLMs trained with a focus on Japanese, along with their evaluation benchmarks, maintained by volunteers from various sources like academic papers and other public resources.
⚠ Caution:
- We can’t guarantee the accuracy or completeness of any information here.
- Some information is based on conjecture and might not reflect your specific use case.
- While many models are released under permissive licenses like MIT or Apache 2.0, some are subject to more restrictive terms including non-commercial use clauses (e.g CC BY-NC-SA 4.0) or other stipulations.
Please point out any errors on the issues page. Feel free to contribute directly with a pull request.
Table of Contents
- Text Generation Models
- Encoder Models
- Sentence and Document Embeddings
- Vision-Language Models
- Speech-Language Models
- Evaluation Benchmarks for Japanese LLMs
- Hybrid Benchmarks
- Traditional Benchmarks based on Natural Language Understanding tasks
- Benchmarks on open-ended generative tasks
- Benchmarks for measuring logical reasoning capabilities
- Benchmarks for measuring performance in specific domains
- Benchmarks for embedding models
- Benchmarks for vision-language models
- References for Models and Architectures
- References for Training Methods
- Our Contributors
- Citation
Text Generation Models
For multimodal models, see below.
Models built from scratch
General purpose
| Architecture | Max Context Length | Training Data | Developer | License | |
|---|---|---|---|---|---|
| LLM-jp-13B v2.0 | Llama (13b-v2.0, 13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0, 13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0, 13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0) |
4,096 | Pre-training: llm-jp-corpus-v2 Instruction Tuning: ichikara-instruction, answer-carefully, Dolly Dataset, OASST1, OASST2 |
LLM-jp | Apache 2.0 |
| LLM-jp-13B v1.1 | GPT (13b-instruct-lora-dolly_en-dolly_ja-ichikara_003_001-oasst_en-oasst_ja-v1.1, 13b-instruct-full-dolly_en-dolly_ja-ichikara_003_001-oasst_en-oasst_ja-v1.1, 13b-dpo-lora-hh_rlhf_ja-v1.1) |
2,048 | Instruction Tuning (LoRA or Full-parameter FT): Dolly Dataset, OASST1, ichikara-instruction DPO (LoRA): HH RLHF |
LLM-jp | Apache 2.0 |
| LLM-jp-13B | GPT (1.3b-v1.0, 13b-v1.0, 13b-instruct-full-jaster-v1.0, 13b-instruct-full-jaster-dolly-oasst-v1.0, 13b-instruct-full-dolly-oasst-v1.0, 13b-instruct-lora-jaster-v1.0, 13b-instruct-lora-jaster-dolly-oasst-v1.0, 13b-instruct-lora-dolly-oasst-v1.0) |
2,048 | Pre-training: llm-jp-corpus (Wikipedia, Japanese mC4, The Pile, Stack) (300B tokens) Instruction Tuning (Full-parameter FT or LoRA): jaster, Dolly Dataset, OASST1 |
LLM-jp | Apache 2.0 |
| PLaMo-13B | Llama1 (13b, 13b-instruct, 13b-instruct-nc) |
base: 4,096 instruct, instruct-nc: 8,192 |
Pre-training: C4, Project Gutenberg, RedPajama, Japanese Wikipedia, Japanese mC4 (1.5T tokens) Instruction Tuning (Full-parameter FT): Dolly, HH RLHF, OASST1, wikinews (+Alpaca in NC model) |
Preferred Networks | Apache 2.0 (CC BY-NC 4.0 as for NC model) |
| Stockmark-13b | Llama (13b, 13b-instruct) |
2,048 | Pre-training: Japanese Wikipedia, Japanese CC-100, Japanese mC4, Japanese CommonCrawl, Japanese Patent, Stockmark Web Corpus (220B tokens) Instruction Tuning (LoRA): ichikara-instruction |
Stockmark | base: MIT instruct: CC BY-NC-SA 4.0 |
| Weblab-10B | GPT-NeoX (10b, 10b-instruction-sft) |
2,048 | Japanese mC4, The Pile (600B tokens) Instruction Tuning (Full-parameter FT): Alpaca, FLAN |
University of Tokyo Matsuo Lab | CC BY‑NC 4.0 |
| Japanese StableLM Alpha | GPT-NeoX (base-alpha-7b, instruct-alpha-7b, instruct-alpha-7b-v2) |
2,048 | Wikipedia, Japanese CC‑100, Japanese mC4, Japanese OSCAR, RedPajama, private datasets2 (750B tokens) Instruction Tuning (Full-parameter FT): Dolly, HH‑RLHF, wikinews, Alpaca (discarded in v2) |
Stability AI | base: Apache 2.0 instruct (v1): Research license instruct (v2): Apache 2.0 |
| CALM2 | Llama (7b, 7b-chat, 7b-chat-dpo-experimental) |
base: 4,096 chat: 32,768 |
publicly available Japanese and English datasets (details unknown) (1.3T tokens) DPO: Chatbot Arena Conversations JA (calm2) Dataset |
CyberAgent | Apache 2.0 (CC BY 4.0 as for DPO model) |
| OpenCALM | GPT-NeoX (small, medium, large, 1b(1.4b), 3b(2.7b), 7b(6.8b)) |
2,048 | Japanese Wikipedia, Japanese mC4, Japanese CC‑100 | CyberAgent | CC BY‑SA 4.0 |
| Stormy | GPT-NeoX (7b(6.8b)) |
2,048 | OpenCALM fine-tuned on llm-japanese-dataset v0 non-translation tasks |
University of Tokyo Izumi Lab | CC BY‑SA 4.0 |
| rinna GPT (En-Ja Bilingual) |
GPT-NeoX (4b(3.8b), 4b(3.8b)-8k, 4b(3.8b)-instruction-sft, 4b(3.8b)-instruction-ppo) |
8k model: 8,192 others: 2,048 |
Wikipedia, Japanese CC‑100, Japanese C4, RedPajama, The Pile (524B tokens) Instruction Tuning (Full-parameter FT): HH‑RLHF, FLAN PPO: HH‑RLHF for reinforcement learning 8k: trained with long context |
rinna | MIT |
| japanese-large-lm | GPT-NeoX (1.7b, 3.6b, 1.7b-instruction-sft, 3.6b-instruction-sft) |
2,048 | Japanese Wikipedia, Japanese CC‑100, Japanese C4, Japanese OSCAR and private datasets (650GB) Instruction Tuning (Full-parameter FT): OASST1 |
LINE | Apache 2.0 |
| rinna GPT (Japanese only) |
GPT-NeoX (xsmall, small, medium, 1b, neox-small, neox-3.6b, neox-3.6b-instruction-sft, neox-3.6b-instruction-sft-v2, neox-3.6b-instruction-ppo) |
≤ 2,048 | Japanese Wikipedia, Japanese CC‑100 (1b and up models add Japanese mC4) Instruction Tuning (Full-parameter FT): HH‑RLHF, FLAN, SHP PPO: HH‑RLHF for reinforcement learning |
rinna | MIT |
| RetrievaT5 | T5 (small (short), small (medium), small (long), base (short), base (medium), base (long), large (short), large (medium), large (long), xl(3b)) |
Japanese Wikipedia, Japanese mC4 | Retrieva | CC BY‑SA 4.0 | |
| kotomamba-2.8B | Mamba (2.8B-v1.0) |
2,048 | Japanese Wikipedia, Swallow Corpus, SlimPajama | Kotoba Technologies | Apache 2.0 |
| ABEJA GPT | GPT-NeoX (large, neox-2.7b) |
Japanese Wikipedia, Japanese CC‑100, Japanese OSCAR | ABEJA | MIT | |
| WasedaGPT | GPT-NeoX (small, xl(1.5b)) |
Japanese Wikipedia, Japanese CC‑100 | Waseda Kawahara Lab | CC BY‑SA 4.0 | |
| StockmarkGPT | GPT-NeoX (1.4b) |
Japanese Wikipedia (0.88B tokens), Japanese CC‑100 (10.5B tokens), private data (8.6B tokens) | Stockmark | MIT | |
| YellowbackGPT | GPT-NeoX (1.3b) |
Japanese Wikipedia, Japanese CC‑100, Japanese OSCAR | Yellowback | Apache 2.0 | |
| colorfulscoop GPT | GPT-NeoX (small) |
Japanese Wikipedia | Colorful Scoop | CC BY‑SA 3.0 | |
| TitechGPT | GPT-NeoX (medium, medium-reversed) 3 |
Japanese Wikipedia, Japanese CC‑100 | Titech Okazaki Lab | CC BY‑SA 4.0 | |
| KyotoUniversityGPT | GPT-NeoX (small, medium, large) |
Japanese Wikipedia (3.2GB), Japanese CC‑100 (85GB), Japanese OSCAR (54GB) | Kyoto University Language Media Processing Lab | CC BY‑SA 4.0 | |
| JapaneseBART | BART (base, large) |
Japanese Wikipedia (18M sentences) | Kyoto University Language Media Processing Lab | CC BY‑SA 4.0 | |
| Megagon Labs T5 | T5 (base) |
Japanese mC4 (782 GB), Japanese wiki40b (2 GB) | Megagon Labs (Recruit Holdings) |
Apache 2.0 |
Domain Specific
| Domain | Architecture | Training Data | Developer | License | |
|---|---|---|---|---|---|
| Japanese Dialog Transformer | Dialog | Transformer | Twitter japanese reply pairs | NTT | Evaluation Licence |
| Japanese News BART | Business | BART (base) | Japanese business news articles (21M articles) | Stockmark | MIT |
| AcademicBART | Science | BART (base) | CiNii Japanese Papers | Ehime University AI Lab | Apache 2.0 |
Models built off English LLMs (w/ continual pre-training on Japanese)
General purpose
| Base Model | Training Data | Developer | License | |
|---|---|---|---|---|
| Swallow 70B (70b-hf, 70b-instruct-hf, 70b-instruct-v0.1, 70b-NVE-hf, 70b-NVE-instruct-hf) |
Llama 2 (70b) | Pre-training: Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, OASST1 *v0.1: OASST1, OASST2 |
TokyoTech-LLM | Llama 2 Community License |
| KARAKURI LM (70b-v0.1, 70b-chat-v0.1) |
Llama 2 (70b) | Pre-training: mC4, CC100, OSCAR, RedPajama, undisclosed dataset (16B tokens) SteerLM: OASST2, undisclosed dataset |
KARAKURI | Llama 2 Community License4 |
| Japanese Stable LM Beta 70B (base-beta-70b, instruct-beta-70b) |
Llama 2 (70b) | Pre-training: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(excluding Books3) (100B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, OASST1 |
Stability AI | Llama 2 Community License |
| Swallow-MX 8x7B (8x7b-NVE-v0.1) |
Mixtral-8x7B-Instruct-v0.1 (46.7b) | Pre-training: Algebraic Stack, Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile, The Vault | TokyoTech-LLM | Apache 2.0 |
| ABEJA-Mixtral-8x7B-japanese (8x7B-v0.1-japanese, 8x7B-Instruct-v0.1-japanese, 8x7B-Instruct-v0.1-japanese-alpha, 8x7B-Instruct-v0.1-japanese-alpha-merged) |
Mixtral-8x7B-Instruct-v0.1 (46.7b) *The model without “Instruct” in its name is based on Mixtral-8x7B-v0.1 |
Pre-training: Japanese CC, Redpajama, undisclosed dataset (450B tokens) |
ABEJA | Apache 2.0 |
| Nekomata 14B (14b, 14b-instruction, 14b-gguf, 14b-instruction-gguf) |
Qwen (14b) | Pre-training: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, undisclosed dataset (66B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, FLAN, subsets of llm-japanese-dataset |
rinna | Tongyi Qianwen LICENSE |
| Swallow 13B (13b-hf, 13b-instruct-hf, 13b-instruct-v0.1, 13b-NVE-hf) |
Llama 2 (13b) | Pre-training: Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, OASST1 *v0.1: OASST1, OASST2 |
TokyoTech-LLM | Llama 2 Community License |
| ELYZA-japanese-Llama-2-13b (13b, 13b-instruct, 13b-fast, 13b-fast-instruct) |
Llama 2 (13b) | Pre-training: Japanese Wikipedia, Japanese OSCAR, and other crawled data (18B tokens) Instruction Tuning: undisclosed dataset |
ELYZA | Llama 2 Community License |
| Llama 3 Youko 8B (8b) |
Llama 3 (8b) | Pre-training: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, undisclosed dataset (22B tokens) |
rinna | Llama 3 Community License |
| Swallow 7B (7b-hf, 7b-instruct-hf, 7b-instruct-v0.1, 7b-NVE-hf, 7b-NVE-instruct-hf, 7b-plus-hf) |
Llama 2 (7b) | Pre-training: Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, OASST1 *v0.1: OASST1, OASST2 |
TokyoTech-LLM | Llama 2 Community License |
| ELYZA-japanese-Llama-2-7b (7b, 7b-instruct, 7b-fast, 7b-fast-instruct) |
Llama 2 (7b) | Pre-training: Japanese Wikipedia, Japanese OSCAR, and other crawled data (18B tokens) Instruction Tuning: undisclosed dataset |
ELYZA | Llama 2 Community License |
| Youri 7B (7b, 7b-instruction, 7b-chat, 7b-gptq, 7b-instruction-gptq, 7b-chat-gptq) |
Llama 2 (7b) | Pre-training: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, undisclosed dataset (40B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, FLAN, subsets of llm-japanese-dataset |
rinna | Llama 2 Community License |
| houou-7b (instruction-7b-v1, instruction-7b-v2) |
Llama 2 (7b) | Instruction-tuned Youri 7B (base) on ichikara-instruction (Full-parameter FT) | MoneyForward | Llama 2 Community License |
| Japanese Stable LM Beta 7B (base-beta-7b, base-ja_vocab-beta-7b, instruct-beta-7b, instruct-ja_vocab-beta-7b) |
Llama 2 (7b) | Pre-training: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(excluding Books3) (100B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, OASST1 |
Stability AI | Llama 2 Community License |
| SambaLingo-Japanese (Base, Chat) |
Llama 2 (7b) | Pre-training: Cultura-X Instruction Tuning: ultrachat_200k DPO: ultrafeedback, cai-conversation-harmless |
SambaNova Systems | Llama 2 Community License (?)5 |
| blue-lizard (blue-lizard) |
Llama 2 (7b) | undisclosed | Deepreneur | Llama 2 Community License |
| Swallow-MS 7B (7b-v0.1, 7b-instruct-v0.1) |
Mistral-7B-v0.1 (7b) | Pre-training: Algebraic Stack, Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning: Dolly Dataset, OASST1 |
TokyoTech-LLM | Apache 2.0 |
| RakutenAI-7B (7B, 7B-instruct, 7B-chat) |
Mistral-7B-v0.1 (7b) | Pre-training: undisclosed Instruction Tuning: Dolly Dataset, OASST1, datasets converted from the train split of NLU datasets (like jaster), undisclosed dataset |
Rakuten | Apache 2.0 |
| Japanese Stable LM Gamma 7B (base-gamma-7b, instruct-gamma-7b) |
Mistral-7B-v0.1 (7b) | Pre-training: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(excluding Books3) (100B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, wikinews subset of llm-japanese-dataset |
Stability AI | Apache 2.0 |
| ChatNTQ JA 7B (7b-v1.0) |
Mistral-7B-v0.1 (7b) | Instruction-tuned Japanese Stable LM Gamma 7B (base) on their own datasets | NTQ Solution | Apache 2.0 |
| Shisa Gamma 7B (7b-v1) |
Mistral-7B-v0.1 (7b) | Instruction-tuned Japanese Stable LM Gamma 7B (base) on ultra-orca-boros-en-ja | AUGMXNT | Apache 2.0 (?)5 |
| Shisa 7B (base-7b-v1, 7b-v1) |
Mistral-7B-v0.1 (7b) | Pre-training: shisa-pretrain-en-ja-v1 (8B tokens) Instruction Tuning(Full-parameter FT) & DPO: ultra-orca-boros-en-ja, shisa-en-ja-dpo-v1 |
AUGMXNT | Apache 2.0 (?)5 |
| Karasu (7B, 7B-chat, 7B-chat-plus, 7B-chat-plus-unleashed) |
Mistral-7B-v0.1 (7b) | Additionally trained Shisa 7B (base) on Aozora Bunko, Japanese Law Precedent Dataset, Japanese Wikipedia, Japanese domain webscrapes from the Japanese subset of CulturaX, UltraChat 200k (7B tokens) Instruction Tuning: ultra-orca-boros-en-ja-v1, OASST1, ShareGPT, undisclosed dataset |
Lightblue | Apache 2.0 (?)5 |
| Nekomata 7B (7b, 7b-instruction, 7b-gguf, 7b-instruction-gguf) |
Qwen (7b) | Pre-training: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, undisclosed dataset (66B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, FLAN, subsets of llm-japanese-dataset |
rinna | Tongyi Qianwen LICENSE |
| lightblue/japanese-mpt-7b | MPT (7b) | Japanese mC4 | Lightblue | Apache 2.0 |
| Japanese Stable LM 3B-4E1T (3b-4e1t-base, 3b-4e1t-instruct) |
StableLM-3B-4E1T (3b) | Pre-training: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(excluding Books3) (100B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, wikinews subset of llm-japanese-dataset |
Stability AI | Apache 2.0 |
| kotomamba-2.8B-CL | mamba-2.8b-slimpj (2.8b) |
Japanese Wikipedia, Swallow Corpus, SlimPajama | Kotoba Technologies | Apache 2.0 |
| karasu-1.1B | TinyLlama (1.1b) | Pre-training: Japanese OSCAR, Japanese mC4 (3B tokens) |
Lightblue | Apache 2.0 |
Domain specific
| Domain | Base Model | Developer | License | |
|---|---|---|---|---|
| AIgroup-CVM-utokyohospital/MedSwallow-70b | Medicine | Llama 2 (70b) | University of Tokyo Hospital Department of Cardiovascular Medicine AI Group | CC BY-NC-SA 4.0 |
| nekomata-14b-pfn-qfin (qfin, qfin-inst-merge) |
Finance | Qwen (14b) | Preferred Networks | Tongyi Qianwen LICENSE |
| Watashiha-Llama-2-13B-Ogiri-sft (sft, sft-neuron) |
Oogiri | Llama 2 (13b) | Watashiha | Llama 2 Community License |
| ELYZA-japanese-CodeLlama-7b (7b, 7b-instruct) |
Coding | Code Llama (7b) |
ELYZA | Llama 2 Community License |
| AIBunCho/japanese-novel-gpt-j-6b | Storytelling | GPT-J (6b) | Individual (Hiroyuki Osone) | CreativeML OpenRAIL-M License |
| NovelAI/genji-jp | Storytelling | GPT-J (6b) | NovelAI | ? |
Models built off English LLMs (w/ instruction tuning on Japanese)
General purpose
| Base Model | Training Data | Developer | License | |
|---|---|---|---|---|
| ao-Karasu (72B) |
Qwen1.5 (72b) | ultra-orca-boros-en-ja-v1, OASST1, ShareGPT, Japanese technical blogs, News stories, QA site answers, undisclosed dataset | Lightblue | Tongyi Qianwen LICENSE (?)5 |
| AIgroup-CVM-utokyohospital/Llama-2-70b-chat-4bit-japanese | Llama 2 (70b) | University of Tokyo Hospital Department of Cardiovascular Medicine AI Group | Llama 2 Community License | |
| doshisha-mil/llama-2-70b-chat-4bit-japanese-v1 | Llama 2 (70b) | Doshisha University Media Informatics Lab | ? | |
| Qarasu (14B-chat-plus-unleashed) |
Qwen (14b) | ultra-orca-boros-en-ja-v1, OASST1, ShareGPT, undisclosed dataset | Lightblue | Tongyi Qianwen LICENSE (?)5 |
| Sparticle/llama-2-13b-chat-japanese-lora | Llama 2 (13b) | Sparticle | ? | |
| izumi-lab/llama-13b-japanese-lora-v0-1ep | Llama (13b) | University of Tokyo Izumi Lab | ? | |
| Llama 3 Suzume 8B (8B-japanese, 8B-japanese-gguf) |
Llama 3 (8b) | megagonlabs/instruction_ja, ShareGPT, undisclosed dataset | Lightblue | Llama 3 Community License (?)5 |
| ganchengguang/Yoko-7B-Japanese-v1 | Llama 2 (7b) | Yokohama National University Mori Lab | ? | |
| Sparticle/llama-2-7b-chat-japanese-lora | Llama 2 (7b) | Sparticle | ? | |
| izumi-lab/llama-7b-japanese-lora-v0-5ep | Llama (7b) | University of Tokyo Izumi Lab | ? | |
| lightblue/jod | Mistral-7B-SlimOrca (7b) | Lightblue | Apache 2.0 | |
| NTQAI/chatntq-7b-jpntuned | RWKV-4 World (7b) | NTQ Solution | ? |
Domain specific
| Domain | Base Model | Developer | License | |
|---|---|---|---|---|
| JMedLoRA (llama2-jmedlora-6.89ep) |
Medicine | Llama 2 (70b) | University of Tokyo Hospital Department of Cardiovascular Medicine AI Group | CC BY-NC 4.0 |
Merged models
| Original Models (Japanese LLMs in bold) | Developer | License | |
|---|---|---|---|
| EvoLLM-JP-A (v1-7B) |
Shisa Gamma 7B (v1), Arithmo2 Mistral 7B, Abel 7B 002 | Sakana AI | Apache 2.0 |
| EvoLLM-JP (v1-7B, v1-10B) |
Shisa Gamma 7B (v1), WizardMath-7B-V1.1, Abel 7B 002 | Sakana AI | MICROSOFT RESEARCH LICENSE |
Encoder models
General purpose
| Architecture | Training Data | Developer | License | HuggingFace? 6 | |
|---|---|---|---|---|---|
| KyotoUniBERT | BERT (base, large) | Japanese Wikipedia (18M articles) | Kyoto University Language Media Processing Lab | Apache 2.0 | △ |
| TohokuUniversityBERT | BERT (base, large) | base (v1): Japanese Wikipedia (17M articles / 2.6GB) base (v2) & large: Japanese Wikipedia 4.0GB base (v3) & large (v2): Japanese Wikipedia (4.9GB), Japanese CC‑100 (74.3GB) |
Tohoku University NLP Group | base (v1, v2) & large: CC BY‑SA 3.0 base (v3) & large (v2): Apache 2.0 |
◯ (base (v1), base (v1, char-level), base (v2), base (v2, char-level), large, large (char-level), base (v3), base (v3, char-level), large (v2), large (v2, char-level)) |
| NICT BERT | BERT (base) | Japanese Wikipedia | NICT | CC BY 4.0 | △ |
| colorfulscoop BERT | BERT (base) | Japanese Wikipedia | Colorful Scoop | CC BY‑SA 3.0 | ◯ |
| UniversityOfTokyoBERT | BERT (small) | Japanese Wikipedia (2.9GB) | University of Tokyo Izumi Lab | CC BY‑SA 4.0 | ◯ |
| chiTra (Sudachi Transformers) | BERT (base) | NINJAL Web Japanese Corpus (148GB) | NINJAL & WAP Tokushima Laboratory of AI and NLP | Apache 2.0 | △ |
| ACCMS BERT | BERT (base) | Japanese Wikipedia (3.3GB) | Kyoto University ACCMS | CC BY‑SA 4.0 | ◯ |
| HitachiBERT | BERT (base) | Japanese Wikipedia, Japanese CC‑100 | Hitachi | CC BY‑NC‑SA 4.0 | ◯7 |
| Bandai Namco DistilBERT | DistilBERT | (Distillation of TohokuUniversityBERT(base)) | Bandai Namco Research | MIT | ◯ |
| LINE DistilBERT | DistilBERT | (Distillation of LINE internal BERT model) | LINE | Apache 2.0 | ◯ |
| rinna RoBERTa | RoBERTa (base) | Japanese Wikipedia, Japanese CC‑100 | rinna | MIT | ◯ |
| WasedaRoBERTa | RoBERTa (base, large) | Japanese Wikipedia, Japanese CC‑100 | Waseda Kawahara Lab | CC BY‑SA 4.0 | ◯ (base, large, large (seq512))8 |
| InformatixRoBERTa | RoBERTa (base) | Japanese Wikipedia, Web Articles (25GB) |
Informatix | Apache 2.0 | △ |
| KyotoUniversityRoBERTa | RoBERTa (base, large) | Japanese Wikipedia, Japanese CC‑100 | Kyoto University Language Media Processing Lab | CC BY‑SA 4.0 | ◯ (base (char-level), large (char-level)) |
| YokohamaNationalRoBERTa | RoBERTa (base) | Japanese Wikipedia (3.45GB) | Yokohama National University Mori Lab | Apache 2.0 | ◯ |
| Megagon Labs RoBERTa | RoBERTa (base)9 | Japanese mC4 (200M sentences) | Megagon Labs (Recruit Holdings) |
MIT | ◯ |
| ACCMS RoBERTa | RoBERTa (base) | Japanese Wikipedia (3.3GB) + Japanese CC‑100 (70GB) | Kyoto University ACCMS | CC BY‑SA 4.0 | ◯ |
| CinnamonELECTRA | ELECTRA (small) | Japanese Wikipedia | Cinnamon | Apache 2.0 | ◯ |
| Megagon Labs ELECTRA | ELECTRA (base) | Japanese mC4 (200M sentences) | Megagon Labs (Recruit Holdings) |
MIT | ◯ |
| UniversityOfTokyoELECTRA | ELECTRA (small, base) | Japanese Wikipedia (2.9GB) | University of Tokyo Izumi Lab | CC BY‑SA 4.0 | ◯ (small, base) |
| JapaneseRoFormer | RoFormer (base) | Japanese Wikipedia (3.45GB) | Yokohama National University Mori Lab | Apache 2.0 | ◯ |
| JapaneseLUKE | LUKE (base, large) | Japanese Wikipedia | Studio Ousia | Apache 2.0 | ◯ (base, large) |
| KyotoUniversityDeBERTaV2 | DeBERTaV2 (tiny, base, large) | Japanese Wikipedia, Japanese CC‑100, Japanese OSCAR (171GB) |
Kyoto University Language Media Processing Lab | CC BY‑SA 4.0 | ◯ (tiny, tiny (char-level), base, large) |
| UniversityOfTokyoDeBERTaV2 | DeBERTaV2 (small, base) | Japanese Wikipedia, Japanese Wikinews, Japanese CC-100, Japanese mC4, Japanese OSCAR | University of Tokyo Izumi Lab | CC BY-SA 4.0 | ◯ (small, base) |
| JapaneseBigBird | BigBird (base) | Japanese Wikipedia, Japanese CC‑100, Japanese OSCAR | Waseda Kawahara Lab | CC BY‑SA 4.0 | ◯ |
| JapaneseLayoutLM | LayoutLM (base) | Pre-trained on Japanese Wikipedia, initialized with TohokuUniversityBERT | The Japan Research Institute, Limited | CC BY-SA 3.0 | ◯ |
Domain Specific
| Architecture | Training Data | Developer | License | HuggingFace? | |
|---|---|---|---|---|---|
| JapaneseNewsBERT | BERT (base) | Japanese Business Articles (3M articles) | Stockmark | CC BY 4.0 | △ |
| JapaneseNewsXLNet | XLNet (base) | Japanese Business Articles (3M articles) | Stockmark | ? | ◯ ※ Unofficial release |
| JapaneseNewsALBERT | ALBERT (base) | Japanese Business Articles (3M articles) | Stockmark | ? | △ |
| Laboro BERT | BERT (base, large) | Japanese Web Corpus (News and blogs, etc) (12GB) |
Laboro.AI | CC BY‑NC 4.0 | ✕ |
| Laboro DistilBERT | DistilBERT | (Distillation of Laboro BERT(base)) | Laboro.AI | CC BY‑NC 4.0 | ◯ |
| JapaneseBlogELECTRA | ELECTRA (small) | Japanese Blog Corpus (354M sentences) | Kitami Institute of Technology Masui-Ptaszynski Lab | CC BY‑SA 4.0 | ◯ |
| JapaneseSpokenLanguageBERT | BERT (base) | Additional training for TohokuUniversityBERT using Corpus of Spontaneous Japanese (CSJ) (In the DAPT model, the diet record is also used) |
Retrieva | Apache 2.0 | ◯ |
| JapaneseFinancialBERT | BERT (small, base)10 | Japanese Wikipedia, Japanese Financial Corpus (27M sentences/5.2GB) | University of Tokyo Izumi Lab | CC BY‑SA 4.0 | ◯ (small, base) |
| JapaneseFinancialELECTRA | ELECTRA (small) | Japanese Wikipedia (20M sentences/2.9GB), Japanese Financial Corpus (27M sentences/5.2GB) | University of Tokyo Izumi Lab | CC BY‑SA 4.0 | ◯ |
| UTH-BERT | BERT (base) | Japanese Medical Records(120M lines) | University of Tokyo Hospital Medical AI Development Course |
CC BY‑NC‑SA 4.0 | △ |
| medBERTjp | BERT (base) | Japanese Wikipedia, Japanese Medical Corpus (“今日の診療プレミアム/Today’s Care Premium” Web Version) | Osaka University Hospital Medical Informatics Lab |
CC BY‑NC‑SA 4.0 | △ |
| JMedRoBERTa | RoBERTa (base) | Japanese Medical Papers (11M sentences/1.8GB) | University of Tokyo Aizawa Lab | CC BY‑NC‑SA 4.0 | ◯ (ManbyoWordPiece, SentencePiece)11 |
| AcademicRoBERTa | RoBERTa (base) | CiNii Japanese Papers (6.3M sentences) | Ehime University AI Lab | Apache 2.0 | ◯ |
Sentence and Document Embeddings
Vision-Language Models
Text+Image to Text
General Purpose
| Architecture | Training Data | Developer | License | |
|---|---|---|---|---|
| EvoVLM-JP (v1-7B) |
- | - (merged from Shisa Gamma 7B (v1) and LLaVA-1.6-Mistral-7B) | Sakana AI | Apache 2.0 |
| Heron (blip-ja-stablelm-base-7b-v0, blip-ja-stablelm-base-7b-v1, blip-ja-stablelm-base-7b-v1-llava-620k, git-ja-stablelm-base-7b-v0, git-ELYZA-fast-7b-v0, git-ja-stablelm-base-7b-v1) |
BLIP-2 / GIT | v1: LLaVA-Instruct-150K-JA or LLaVA-Instruct-620K-JA v0: LLaVA-Instruct-150K-JA, Japanese STAIR Captions, Japanese Visual Genome VQA dataset |
Turing | CC BY-NC 4.0 |
| Japanese Stable VLM (japanese-stable-vlm) |
LLaVA-1.5 | Japanese CC12M, STAIR Captions, Japanese Visual Genome VQA dataset | Stability AI | STABILITY AI JAPANESE STABLE VLM COMMUNITY LICENSE |
| Japanese InstructBLIP Alpha (japanese-instructblip-alpha) |
InstructBLIP | Japanese CC12M, STAIR Captions, Japanese Visual Genome VQA dataset | Stability AI | JAPANESE STABLELM RESEARCH LICENSE |
| rinna MiniGPT-4 (bilingual-gpt-neox-4b-minigpt4) |
MiniGPT-4 | CC12M, COCO 2014, Visual Genome, STAIR Captions, Japanese Visual Genome VQA dataset | rinna | MIT |
Domain Specific
| Architecture | Domain | Developer | License | |
|---|---|---|---|---|
| watashiha/Watashiha-Llama-2-13B-Ogiri-sft-vlm | LLaVA | Oogiri | Watashiha | Llama 2 Community License |
Text to Image
| Architecture | Training Data | Developer | License | |
|---|---|---|---|---|
| EvoSDXL-JP (v1) |
- | - (merged from several diffusion models, including Japanese Stable Diffusion XL) | Sakana AI | Apache 2.012 |
| Japanese Stable Diffusion XL (japanese-stable-diffusion-xl) |
Stable Diffusion | undisclosed | Stability AI | STABILITY AI JAPANESE STABLE DIFFUSION XL COMMUNITY LICENSE |
| TohokuUniversity Stable Diffusion (base, refiner) |
Stable Diffusion | WMT2023 Shared Task English-Japanese parallel corpus, about 13 million captions from laion2B-multi | Tohoku University NLP Group | CreativeML OpenRAIL-M License |
| rinna Stable Diffusion (japanese-stable-diffusion) |
Stable Diffusion | LAION-5B Japanese Subset (100M images) | rinna | CreativeML OpenRAIL-M License |
Others
| Architecture | Training Data | Developer | License | |
|---|---|---|---|---|
| Recruit CLIP (japanese-clip-vit-b-32-roberta-base) |
CLIP | about 120 million captions from laion2B-multi | Recruit Holdings | CC BY-4.0 |
| Japanese Stable CLIP (japanese-stable-clip-vit-l-16) |
SigLIP | CC12M translated to Japanese, STAIR Captions | Stability AI | STABILITY AI JAPANESE STABLE CLIP COMMUNITY LICENSE |
| rinna CLIP (japanese-clip-vit-b-16) |
CLIP | CC12M translated to Japanese | rinna | Apache 2.0 |
| rinna CLOOB (japanese-cloob-vit-b-16) |
CLOOB | CC12M translated to Japanese | rinna | Apache 2.0 |
| HAKUHODO Technologies CLIP (base, deeper, wider) |
CLIP | about 120 million captions from laion2B-multi | HAKUHODO Technologies | CC BY-NC-SA 4.0 |
Speech-Language Models
Automatic Speech Recognition
| Architecture | Training Data | Developer | License | |
|---|---|---|---|---|
| Kotoba-Whisper (v1.0, v1.0-ggml) |
Distil-Whisper | ReazonSpeech | Kotoba Technologies | Apache 2.0 |
| Nue ASR (nue-asr) |
Nue ASR (HuBERT + LLM) |
ReazonSpeech | rinna | Apache 2.0 |
| ReazonSpeech (espnet-v1, espnet-next, espnet-v2, nemo-v2) |
ESPnet (Conformer-Transducer) / NeMo (FastConformer-RNNT) | ReazonSpeech | Reazon Holdings | Apache 2.0 |
Others
| Architecture | Training Data | Developer | License | |
|---|---|---|---|---|
| Kotoba-Speech (v0.1) |
Transformer | undisclosed | Kotoba Technologies | Apache 2.0 |
| UniversityOfTokyoHuBERT (base-jtube) |
HuBERT | JTubeSpeech | University of Tokyo Saruwatari & Takamichi Lab |
MIT |
| rinna HuBERT (base, large) |
HuBERT | ReazonSpeech | rinna | Apache 2.0 |
Evaluation Benchmarks for Japanese LLMs
Hybrid Benchmarks
Nejumi LLM Leaderboard Neo (Weights & Biases)
This compiles the results of a comprehensive evaluation by llm-jp-eval, which evaluates language understanding in a question-and-answer format, and Japanese MT-bench, which evaluates generative ability in a context of dialogue prompts.
Traditional Benchmarks based on Natural Language Understanding tasks
llm-jp-eval (LLM-jp)
A tool that evaluates Japanese LLMs automatically across multiple datasets.
The complete list of supported datasets can be found here (which also includes tasks such as JNLI and JCommonsenseQA from JGLUE).
Evaluation results are compiled on the llm-jp-eval leaderboard.
JP Language Model Evaluation Harness (Stability AI)
A fork by Stability AI of EleutherAI/lm-evaluation-harness. It is a tool for automatically evaluating Japanese LLMs across multiple datasets.
The complete list of supported datasets can be found here (which also includes tasks such as JNLI and JCommonsenseQA from JGLUE).
There is a detailed summary of the evaluation results by rinna: [rinna] Benchmark of Stability-AI/lm-evaluation-harness
JGLUE (Waseda University Kawahara Lab and Yahoo)
Japanese version of the GLUE benchmark suite, including the MARC-ja, JCoLA, JSTS, JNLI, JSQuAD, and JCommonsenseQA tasks. JCoLA is by the University of Tokyo’s Oseki Lab. See here and here (ja only) for further details about each task.
JMMLU (Waseda University Kawahara Lab)
A benchmark constructed as a Japanese version of the MMLU Benchmark, consisting of multiple-choice questions from a wide range of academic fields including natural sciences, humanities, and social sciences. In addition to translating the original MMLU, it features newly added problems based on the unique cultural background of Japan (Japan-specific problems).
Japanese Open LLM Leaderboard (LLM-jp)
Similar to Huggingface’s Open LLM Leaderboard, this leaderboard provides a verification on Japanese LLMs. You can check the performance of Japanese LLMs in English tasks.
Benchmarks on open-ended generative tasks
Japanese MT-bench (Stability AI)
The Japanese version of MT-bench asks about multi-turn conversational ability. It includes 80 questions, 10 each, from 8 categories: Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, Humanities. Some questions have been modified to fit with Japanese culture during the production of the Japanese version. It also includes a script that performs a 10-level absolute evaluation by GPT-4.
Rakuda Benchmark (YuzuAI)
Ranking based on model answers to 40 open-ended questions on Japanese geography, history, politics, and society. Uses GPT-4 to judge model outputs pairwise, and then ranks models by fitting a Maximum Likelihood Elo/Bradley-Terry model to GPT-4’s preferences. See here for the data and code used to generate the ranking and here for further explanation.
ELYZA-tasks-100 (ELYZA)
Ranking based on model responses to 100 complex and diverse tasks, including tasks testing summarization, correction, abstraction, induction, and other skills. Uses humans to score the model responses and then ranks models based on their mean scores. Evaluation results can be found here and here. For an evaluation containing newer models, see here.
Japanese Vicuna QA Benchmark (Kyoto University Language Media Processing Lab)
This is the Japanese version of vicuna-blog-eval, which is the predecessor of MT-Bench. It includes 80 questions on general knowledge, role-playing, common sense, Fermi estimation, counterfactual thinking, coding, mathematics, and writing. It also includes a script for automatic evaluation by GPT-4 (win-rate calculation). The leaderboard can be found here.
Benchmarks for measuring logical reasoning capabilities
JFLD (Japanese Formal Logic Deduction) (Hitachi)
A dataset for evaluating deductive reasoning capabilities of Japanese LLMs (the Japanese version of the FLD (Formal Logic Deduction) proposed by the same authors). It is characterized by being composed of counterfactual samples to evaluate apart from the knowledge the LLM possesses.
JHumanEval (Japan Women’s University Kuramitsu Lab)
A Japanese version of the HumanEval benchmark, which assesses the ability to generate Python code from English instructions. In creating the Japanese version, the text was first machine-translated and then manually corrected.
Benchmarks for measuring performance in specific domains
Japanese Language Model Financial Evaluation Harness (Preferred Networks)
A benchmark for Japanese LLM in the financial sector. It includes tasks such as sentiment analysis in finance (chabsa), basic knowledge tasks in securities analysis (cma_basics), tasks related to audits in certified public accountant examinations (cpa_audit), multiple choice question tasks in financial planner exams (fp2), and mock exam tasks for securities salespeople exams (security_sales_1). For more details, please see here.
Stockmark Business Questions (Stockmark)
The collection includes 50 questions that probe knowledge on topics such as market trends, current affairs, social issues, and business trends.
Benchmarks for embedding models
JMTEB (SB Intuitions)
A benchmark developed as the Japanese version of MTEB. It consists of tasks such as document clustering, text classification, sentence similarity, sentence pair labeling prediction, and text extraction (a reranking task was recently added).
Benchmarks for vision-language models
Heron-Bench (Turing)
21 images are assigned a total of 102 questions. It is characterized by image-question pairs that require knowledge related to Japan.
JA-VLM-Bench-In-the-Wild (Sakana AI)
A dataset independently prepared by Sakana AI to evaluate EvoVLM-JP-v1-7B. It consists of 50 questions assigned to 42 images. It is characterized by images and questions that require knowledge about Japan.
LLaVA-Bench-In-the-Wild (Japanese) (Turing)
This is the Japanese version of LLaVA-Bench-In-the-Wild, translated using DeepL. It consists of 60 questions assigned to 24 images.
LLaVA-Bench (COCO) Japanese (Turing)
This is the Japanese version, translated by DeepL, of the LLaVA-Bench (COCO) dataset used to evaluate LLaVA. It consists of 30 images, each with 3 types of questions assigned to them.
References for Models and Architectures
References for Training Methods
| Model/Architecture | Date | Meeting/Journal | Paper |
|---|---|---|---|
| PPO (RLHF) | 2017.07.20 | - | Proximal Policy Optimization Algorithms |
| Instruction Tuning (Supervised Fine-tuning; SFT) |
2021.09.03 | ICLR 2022 | Finetuned Language Models Are Zero-Shot Learners |
| DPO | 2023.05.29 | NeurIPS 2023 | Direct Preference Optimization: Your Language Model is Secretly a Reward Model |
| SteerLM | 2023.10.09 | Findings of EMNLP 2023 | SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF |
Our Contributors
We love contributors! Feel free to contribute to this project.

Citation
The summary of this repository is also published as a preprint: Exploring Open Large Language Models for the Japanese Language: A Practical Guide
When referencing this repository, please cite as follows:
@article{awesomeJapanese2024,
title={{Exploring Open Large Language Models for the Japanese Language: A Practical Guide}},
author={Kaito Sugimoto},
doi={10.51094/jxiv.682},
journal={Jxiv preprint},
year={2024}
}
-
Some performance enhancements have been made to the original Llama model. See here for details. ↩
-
Details have not been made public but the private dataset includes data from the EleutherAI Polyglot project’s Japanese team and from members of Stable Community Japan. ↩
-
This project conducted evaluation research on using right-to-left generation instead of the usual left-to-right generation, releasing both left-to-right and right-to-left models. ↩
-
However, if commercial use of KARAKURI LM is desired, direct contact with the developer, KARAKURI Inc., is required. ↩
-
In Instruction Tuning, because it uses data generated by OpenAI’s models, such as GPT-3.5 and GPT-4, for training, there is a possibility that it may violate OpenAI’s terms. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
-
○: The model is on the HuggingFace Model Hub and can be loaded in with the
AutoModel.from_pretrained()command. △: The model is not on the Model Hub but can be loaded in manually with the HuggingFace transformers library. ✕: The model is not directly loadable with HuggingFace. ↩ -
This project conducted evaluation research on pre-tokenization morphological analysis and released their best performing model, which used Juman++ and BPE. ↩
-
nlp-waseda/roberta-base-japanese and nlp-waseda/roberta-large-japanese trained using a 128 token context length, but nlp-waseda/roberta-large-japanese-seq512 expanded the context length to 512. ↩
-
Extended to a 1282 context length from the usual 512. ↩
-
The “small” model trains on Japanese Wikipedia and the Japanese Financial Corpus simultaneously, while the “base” model takes the TohokuUniversityBERT and conducts additional training on the Japanese Financial Corpus. ↩
-
ManbyoWordPiece conducts a pre-tokenization step using MeCab (IPA+Manbyo dictionaries) and uses WordPiece for subword tokenization, while the SentencePiece model tokenizes text directly using a unigram model. ↩
-
However, it calls for consideration for use in research and education. Additionally, be aware that some of the licenses for the source models are not Apache 2.0. ↩