awesome-japanese-llm
Aperçu des grands modèles de langage (LLM) en japonais
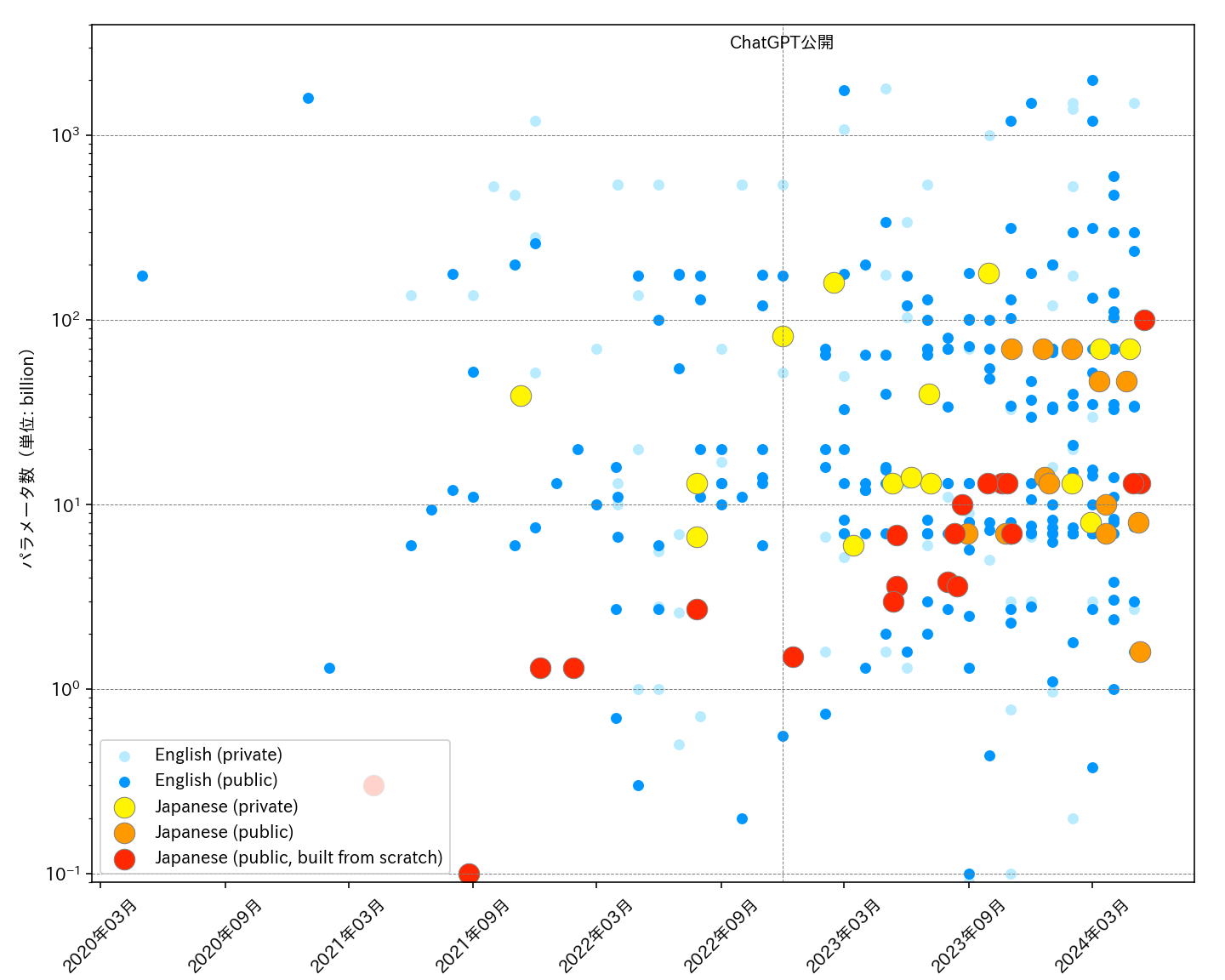
Voici une liste des LLMs disponibles au grand public, axés sur l’apprentissage du japonais, ainsi que leurs critères d’évaluation. Cette liste est maintenue par des bénévoles qui collectent des informations à partir de diverses sources telles que des articles académiques et d’autres ressources publiques.
⚠ Attention:
- Nous ne pouvons garantir l’exactitude ou l’exhaustivité des informations présentées ici.
- Certaines informations sont basées sur des conjectures et peuvent ne pas refléter votre cas d’utilisation spécifique.
- Bien que de nombreux modèles soient publiés sous des licences permissives telles que MIT ou Apache 2.0, certains modèles sont soumis à des conditions plus restrictives, notamment des clauses d’utilisation non commerciale (exemple CC BY-NC-SA 4.0) ou d’autres modalités légales et contractuelles
N’hésitez pas à signaler les erreurs sur la page issues. N’hésitez pas également à contribuer directement avec une pull request.
Table des matières
- Modèles IA génératives
- Modèles encodeur
- Plongement lexical par mots et par documents
- Modèles Vision-Language
- Modèles Speech-Language
- Standard d’évaluation pour les LLM en japonais
- Benchmarks hybrides
- Référence traditionnelle basé sur des tâches de Compréhension du langage naturel (NLU)
- Standard des tâches génératives ouvertes
- Benchmarks pour mesurer les capacités de raisonnement logique
- Benchmarks pour mesurer la performance dans des domaines spécifiques
- Benchmarks pour modèles d’embeddings
- Benchmarks pour modèles vision-language
- Références pour les modèles et les architectures
- Références pour les méthodes d’entraînement
- Nos contributors
- Citation
Modèles IA génératives
Pour les modèles multimodal, voir ci-dessous.
Modèles développés à partir de zéro
D’usage général
| Architecture | Longueur Maximale du Contexte | Données d’entraînement | Développeur | Licence | |
|---|---|---|---|---|---|
| LLM-jp-13B v2.0 | Llama (13b-v2.0, 13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0, 13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0, 13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0) |
4,096 | Pre-training: llm-jp-corpus-v2 Instruction Tuning: ichikara-instruction, answer-carefully, Dolly Dataset, OASST1, OASST2 |
LLM-jp | Apache 2.0 |
| LLM-jp-13B v1.1 | GPT (13b-instruct-lora-dolly_en-dolly_ja-ichikara_003_001-oasst_en-oasst_ja-v1.1, 13b-instruct-full-dolly_en-dolly_ja-ichikara_003_001-oasst_en-oasst_ja-v1.1, 13b-dpo-lora-hh_rlhf_ja-v1.1) |
2,048 | Instruction Tuning (LoRA or Full-parameter FT): Dolly Dataset, OASST1, ichikara-instruction DPO (LoRA): HH RLHF |
LLM-jp | Apache 2.0 |
| LLM-jp-13B | GPT (1.3b-v1.0, 13b-v1.0, 13b-instruct-full-jaster-v1.0, 13b-instruct-full-jaster-dolly-oasst-v1.0, 13b-instruct-full-dolly-oasst-v1.0, 13b-instruct-lora-jaster-v1.0, 13b-instruct-lora-jaster-dolly-oasst-v1.0, 13b-instruct-lora-dolly-oasst-v1.0) |
2,048 | Pré-entraînement: llm-jp-corpus (Wikipedia, Japanese mC4, The Pile, Stack) (300B tokens) Instruction Tuning (Full-parameter FT or LoRA): jaster, Dolly Dataset, OASST1 |
LLM-jp | Apache 2.0 |
| PLaMo-13B | Llama1 (13b, 13b-instruct, 13b-instruct-nc) |
base: 4,096 instruct, instruct-nc: 8,192 |
Pré-entraînement: C4, Project Gutenberg, RedPajama, Japanese Wikipedia, Japanese mC4 (1.5T tokens) Instruction Tuning (Full-parameter FT): Dolly, HH RLHF, OASST1, wikinews (+Alpaca in NC model) |
Preferred Networks | Apache 2.0 (CC BY-NC 4.0 as for NC model) |
| Stockmark-13b | Llama (13b, 13b-instruct) |
2,048 | Wikipedia en japonais, Japanese CC-100, Japanese mC4, Japanese CommonCrawl, Japanese Patent, Stockmark Web Corpus (220B tokens) Instruction Tuning (LoRA): ichikara-instruction |
Stockmark | base: MIT instruct: CC BY-NC-SA 4.0 |
| Weblab-10B | GPT-NeoX (10b, 10b-instruction-sft) |
2,048 | Japanese mC4, The Pile (600B tokens) Instruction Tuning (Full-parameter FT): Alpaca, FLAN |
Université de Tokyo Matsuo Lab | CC BY‑NC 4.0 |
| Japanese StableLM Alpha | GPT-NeoX (base-alpha-7b, instruct-alpha-7b, instruct-alpha-7b-v2) |
2,048 | Wikipédia, Japanese CC‑100, Japanese mC4, Japanese OSCAR, RedPajama, ensembles de données privés2 (750B tokens) Instruction Tuning (Full-parameter FT): Dolly, HH‑RLHF, wikinews, Alpaca (discarded in v2) |
Stability AI | base: Apache 2.0 instruct (v1): Research license instruct (v2): Apache 2.0 |
| CALM2 | Llama (7b, 7b-chat, 7b-chat-dpo-experimental) |
base: 4,096 chat: 32,768 |
Ensembles de données japonais et anglais accessibles au public (détails inconnus) (1.3T tokens) DPO: Chatbot Arena Conversations JA (calm2) Dataset |
CyberAgent | Apache 2.0 (CC BY 4.0 as for DPO model) |
| OpenCALM | GPT-NeoX (small, medium, large, 1b(1.4b), 3b(2.7b), 7b(6.8b)) |
2,048 | Wikipedia en japonais, Japanese mC4, Japanese CC‑100 | CyberAgent | CC BY‑SA 4.0 |
| Stormy | GPT-NeoX (7b(6.8b)) |
2,048 | OpenCALM fine-tuned sur llm-japanese-dataset v0 sans âches de traduction |
Université de Tokyo Izumi Lab | CC BY‑SA 4.0 |
| rinna GPT (En-Ja Bilingual) |
GPT-NeoX (4b(3.8b), 4b(3.8b)-8k, 4b(3.8b)-instruction-sft, 4b(3.8b)-instruction-ppo) |
8k model: 8,192 others: 2,048 |
Wikipedia, Japanese CC‑100, Japanese C4, RedPajama, The Pile (524B tokens) Instruction Tuning (Full-parameter FT): HH‑RLHF, FLAN PPO: HH‑RLHF par apprentissage par renforcement 8k: entrainé sur du long texte |
rinna | MIT |
| japanese-large-lm | GPT-NeoX (1.7b, 3.6b, 1.7b-instruction-sft, 3.6b-instruction-sft) |
2,048 | Wikipedia en japonais, Japanese CC‑100, Japanese C4, Japanese OSCAR et ensembles de données privés (650GB) Instruction Tuning (Full-parameter FT): OASST1 |
LINE | Apache 2.0 |
| rinna GPT (Japanese only) |
GPT-NeoX (xsmall, small, medium, 1b, neox-small, neox-3.6b, neox-3.6b-instruction-sft, neox-3.6b-instruction-sft-v2, neox-3.6b-instruction-ppo) |
≤ 2,048 | Wikipédia en japonais, Japanese CC‑100 (1b et plus modèles à ajouter Japanese mC4) Instruction Tuning (Full-parameter FT): HH‑RLHF, FLAN, SHP PPO: HH‑RLHF par apprentissage par renforcement |
rinna | MIT |
| RetrievaT5 | T5 (small (short), small (medium), small (long), base (short), base (medium), base (long), large (short), large (medium), large (long), xl(3b)) |
Wikipédia en japonais, Japanese mC4 | Retrieva | CC BY‑SA 4.0 | |
| kotomamba-2.8B | Mamba (2.8B-v1.0) |
2,048 | Wikipedia en japonais, Swallow Corpus, SlimPajama | Kotoba Technologies | Apache 2.0 |
| ABEJA GPT | GPT-NeoX (large, neox-2.7b) |
Japanese Wikipedia, Japanese CC‑100, Japanese OSCAR | ABEJA | MIT | |
| WasedaGPT | GPT-NeoX (small, xl(1.5b)) |
Wikipédia en japonais, Japanese CC‑100 | Université de Waseda Kawahara Lab | CC BY‑SA 4.0 | |
| StockmarkGPT | GPT-NeoX (1.4b) |
Wikipédia en japonais (0.88B tokens), Japanese CC‑100 (10.5B tokens), ensembles de données privés (8.6B tokens) | Stockmark | MIT | |
| YellowbackGPT | GPT-NeoX (1.3b) |
Wikipédia en japonais, Japanese CC‑100, Japanese OSCAR | Yellowback | Apache 2.0 | |
| colorfulscoop GPT | GPT-NeoX (small) |
Wikipédia en japonais | Colorful Scoop | CC BY‑SA 3.0 | |
| TitechGPT | GPT-NeoX (medium, medium-reversed) 3 |
Wikipédia en japonais, Japanese CC‑100 | Titech Okazaki Lab | CC BY‑SA 4.0 | |
| KyotoUniversityGPT | GPT-NeoX (small, medium, large) |
Wikipédia en japonais (3.2GB), Japanese CC‑100 (85GB), Japanese OSCAR (54GB) | Université de Kyoto Laboratoire de traitement des langues et des médias | CC BY‑SA 4.0 | |
| JapaneseBART | BART (base, large) |
Wikipédia en japonais (18M sentences) | Université de Kyoto Laboratoire de traitement des langues et des médias | CC BY‑SA 4.0 | |
| Megagon Labs T5 | T5 (base) |
Japanese mC4 (782 GB), Wikipédia en japonais 40b (2 GB) | Megagon Labs (Recruit Holdings) |
Apache 2.0 |
Spécifique à un domaine
| Domaine | Architecture | Données d’entraînement | Développeur | Licence | |
|---|---|---|---|---|---|
| Japanese Dialog Transformer | Dialogue | Transformer | Pairs de réponses venant de Twitter | NTT | License en évaluaiton |
| Japanese News BART | Affaires | BART (base) | Articles de l’actualité économique en japonais (21M articles) | Stockmark | MIT |
| AcademicBART | Science | BART (base) | CiNii Japanese Papers | Université d’Ehime AI Lab | Apache 2.0 |
Modèles développés à partir d’LLM en anglais (avec une apprentissage continue en japonais)
D’usage général
| Base du Model | Données d’entraînement | Développeur | Licence | |
|---|---|---|---|---|
| Swallow 70B (70b-hf, 70b-instruct-hf, 70b-instruct-v0.1, 70b-NVE-hf, 70b-NVE-instruct-hf) |
Llama 2 (70b) | Pre-training: Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, OASST1 *v0.1: OASST1, OASST2 |
TokyoTech-LLM | Llama 2 Community License |
| KARAKURI LM (70b-v0.1, 70b-chat-v0.1) |
Llama 2 (70b) | Pre-training: mC4, CC100, OSCAR, RedPajama, undisclosed dataset (16B tokens) SteerLM: OASST2, undisclosed dataset |
KARAKURI | Llama 2 Community License4 |
| Japanese Stable LM Beta 70B (base-beta-70b, instruct-beta-70b) |
Llama 2 (70b) | Pre-training: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(excluding Books3) (100B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, OASST1 |
Stability AI | Llama 2 Community License |
| Swallow-MX 8x7B (8x7b-NVE-v0.1) |
Mixtral-8x7B-Instruct-v0.1 (46.7b) | Pre-training: Algebraic Stack, Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile, The Vault | TokyoTech-LLM | Apache 2.0 |
| ABEJA-Mixtral-8x7B-japanese (8x7B-v0.1-japanese, 8x7B-Instruct-v0.1-japanese, 8x7B-Instruct-v0.1-japanese-alpha, 8x7B-Instruct-v0.1-japanese-alpha-merged) |
Mixtral-8x7B-Instruct-v0.1 (46.7b) *Le modèle sans “Instruct” dans son nom est basé sur Mixtral-8x7B-v0.1 |
Pre-training: Japanese CC, Redpajama, undisclosed dataset (450B tokens) |
ABEJA | Apache 2.0 |
| Nekomata 14B (14b, 14b-instruction, 14b-gguf, 14b-instruction-gguf) |
Qwen (14b) | Pre-training: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, undisclosed dataset (66B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, FLAN, subsets of llm-japanese-dataset |
rinna | Tongyi Qianwen LICENSE |
| Swallow 13B (13b-hf, 13b-instruct-hf, 13b-instruct-v0.1, 13b-NVE-hf) |
Llama 2 (13b) | Pre-training: Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, OASST1 *v0.1: OASST1, OASST2 |
TokyoTech-LLM | Llama 2 Community License |
| LEIA-Swallow-13B (13b) |
Llama 2 (13b) | additionally trained Swallow 13B using LEIA | Individual (Ikuya Yamada & Ryokan Ri) | Llama 2 Community License |
| ELYZA-japanese-Llama-2-13b (13b, 13b-instruct, 13b-fast, 13b-fast-instruct) |
Llama 2 (13b) | Pre-training: Japanese Wikipedia, Japanese OSCAR, and other crawled data (18B tokens) Instruction Tuning: undisclosed dataset |
ELYZA | Llama 2 Community License |
| Llama 3 Youko 8B (8b) |
Llama 3 (8b) | Pre-training: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, undisclosed dataset (22B tokens) |
rinna | Llama 3 Community License |
| Swallow 7B (7b-hf, 7b-instruct-hf, 7b-instruct-v0.1, 7b-NVE-hf, 7b-NVE-instruct-hf, 7b-plus-hf) |
Llama 2 (7b) | Pre-training: Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, OASST1 *v0.1: OASST1, OASST2 |
TokyoTech-LLM | Llama 2 Community License |
| LEIA-Swallow-7B (7b) |
Llama 2 (7b) | additionally trained Swallow 7B using LEIA | Individual (Ikuya Yamada & Ryokan Ri) | Llama 2 Community License |
| ELYZA-japanese-Llama-2-7b (7b, 7b-instruct, 7b-fast, 7b-fast-instruct) |
Llama 2 (7b) | Pre-training: Japanese Wikipedia, Japanese OSCAR, and other crawled data (18B tokens) Instruction Tuning: undisclosed dataset |
ELYZA | Llama 2 Community License |
| Youri 7B (7b, 7b-instruction, 7b-chat, 7b-gptq, 7b-instruction-gptq, 7b-chat-gptq) |
Llama 2 (7b) | Pre-training: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, undisclosed dataset (40B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, FLAN, subsets of llm-japanese-dataset |
rinna | Llama 2 Community License |
| houou-7b (instruction-7b-v1, instruction-7b-v2) |
Llama 2 (7b) | Instruction-tuned Youri 7B (base) on ichikara-instruction (Full-parameter FT) | MoneyForward | Llama 2 Community License |
| Japanese Stable LM Beta 7B (base-beta-7b, base-ja_vocab-beta-7b, instruct-beta-7b, instruct-ja_vocab-beta-7b) |
Llama 2 (7b) | Pre-training: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(excluding Books3) (100B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, OASST1 |
Stability AI | Llama 2 Community License |
| SambaLingo-Japanese (Base, Chat) |
Llama 2 (7b) | Pre-training: Cultura-X Instruction Tuning: ultrachat_200k DPO: ultrafeedback, cai-conversation-harmless |
SambaNova Systems | Llama 2 Community License (?)5 |
| blue-lizard (blue-lizard) |
Llama 2 (7b) | undisclosed | Deepreneur | Llama 2 Community License |
| Swallow-MS 7B (7b-v0.1, 7b-instruct-v0.1) |
Mistral-7B-v0.1 (7b) | Pre-training: Algebraic Stack, Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning: Dolly Dataset, OASST1 |
TokyoTech-LLM | Apache 2.0 |
| RakutenAI-7B (7B, 7B-instruct, 7B-chat) |
Mistral-7B-v0.1 (7b) | Pre-training: undisclosed Instruction Tuning: Dolly Dataset, OASST1, datasets converted from the train split of NLU datasets (like jaster), undisclosed dataset |
Rakuten | Apache 2.0 |
| Japanese Stable LM Gamma 7B (base-gamma-7b, instruct-gamma-7b) |
Mistral-7B-v0.1 (7b) | Pre-training: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(excluding Books3) (100B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, wikinews subset of llm-japanese-dataset |
Stability AI | Apache 2.0 |
| ChatNTQ JA 7B (7b-v1.0) |
Mistral-7B-v0.1 (7b) | Instruction-tuned Japanese Stable LM Gamma 7B (base) on their own datasets | NTQ Solution | Apache 2.0 |
| Shisa Gamma 7B (7b-v1) |
Mistral-7B-v0.1 (7b) | Instruction-tuned Japanese Stable LM Gamma 7B (base) on ultra-orca-boros-en-ja | AUGMXNT | Apache 2.0 (?)5 |
| Shisa 7B (base-7b-v1, 7b-v1) |
Mistral-7B-v0.1 (7b) | Pre-training: shisa-pretrain-en-ja-v1 (8B tokens) Instruction Tuning(Full-parameter FT) & DPO: ultra-orca-boros-en-ja, shisa-en-ja-dpo-v1 |
AUGMXNT | Apache 2.0 |
| Karasu (7B, 7B-chat, 7B-chat-plus, 7B-chat-plus-unleashed) |
Mistral-7B-v0.1 (7b) | Additionally trained Shisa 7B (base) on Aozora Bunko, Japanese Law Precedent Dataset, Japanese Wikipedia, Japanese domain webscrapes from the Japanese subset of CulturaX, UltraChat 200k (7B tokens) Instruction Tuning: ultra-orca-boros-en-ja-v1, OASST1, ShareGPT, undisclosed dataset |
Lightblue | Apache 2.0 (?)5 |
| Nekomata 7B (7b, 7b-instruction, 7b-gguf, 7b-instruction-gguf) |
Qwen (7b) | Pre-training: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, undisclosed dataset (66B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, FLAN, subsets of llm-japanese-dataset |
rinna | Tongyi Qianwen LICENSE |
| lightblue/japanese-mpt-7b | MPT (7b) | Japanese mC4 | Lightblue | Apache 2.0 (?)5 |
| Japanese Stable LM 3B-4E1T (3b-4e1t-base, 3b-4e1t-instruct) |
StableLM-3B-4E1T (3b) | Pre-training: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(excluding Books3) (100B tokens) Instruction Tuning (Full-parameter FT): Dolly Dataset, HH RLHF, wikinews subset of llm-japanese-dataset |
Stability AI | Apache 2.0 |
| kotomamba-2.8B-CL | mamba-2.8b-slimpj (2.8b) |
Japanese Wikipedia, Swallow Corpus, SlimPajama | Kotoba Technologies | Apache 2.0 |
| karasu-1.1B | TinyLlama (1.1b) | Pre-training: Japanese OSCAR, Japanese mC4 (3B tokens) |
Lightblue | Apache 2.0 |
Spécifique à un domaine
| Domaine | Base du Model | Développeur | Licence | |
|---|---|---|---|---|
| AIgroup-CVM-utokyohospital/MedSwallow-70b | Médecine | Llama 2 (70b) | Université de Tokyo - AI Group du Département hospitalier de médecine cardiovasculaire | CC BY-NC-SA 4.0 |
| nekomata-14b-pfn-qfin (qfin, qfin-inst-merge) |
Finance | Qwen (14b) | Preferred Networks | Tongyi Qianwen LICENSE |
| Watashiha-Llama-2-13B-Ogiri-sft (sft, sft-neuron) |
Oogiri | Llama 2 (13b) | Watashiha | Llama 2 Community License |
| ELYZA-japanese-CodeLlama-7b (7b, 7b-instruct) |
Codage | Code Llama (7b) |
ELYZA | Llama 2 Community License |
| AIBunCho/japanese-novel-gpt-j-6b | Génération de récits | GPT-J (6b) | Individuel (Hiroyuki Osone) | CreativeML OpenRAIL-M License |
| NovelAI/genji-jp | Génération de récits | GPT-J (6b) | NovelAI | ? |
Modèles développés à partir d’LLM en anglais (avec un affinement par instructions en japonais)
D’usage général
| Base du Model | Données d’entraînement | Développeur | Licence | |
|---|---|---|---|---|
| ao-Karasu (72B) |
Qwen1.5 (72b) | ultra-orca-boros-en-ja-v1, OASST1, ShareGPT, Japanese technical blogs, News stories, QA site answers, undisclosed dataset | Lightblue | Tongyi Qianwen LICENSE (?)5 |
| AIgroup-CVM-utokyohospital/Llama-2-70b-chat-4bit-japanese | Llama 2 (70b) | Université de Tokyo - AI Group du Département hospitalier de médecine cardiovasculaire | Llama 2 Community License | |
| doshisha-mil/llama-2-70b-chat-4bit-japanese-v1 | Llama 2 (70b) | Université de Doshisha Media Informatics Lab | ? | |
| Qarasu (14B-chat-plus-unleashed) |
Qwen (14b) | ultra-orca-boros-en-ja-v1, OASST1, ShareGPT, undisclosed dataset | Lightblue | Tongyi Qianwen LICENSE (?)5 |
| Sparticle/llama-2-13b-chat-japanese-lora | Llama 2 (13b) | Sparticle | ? | |
| izumi-lab/llama-13b-japanese-lora-v0-1ep | Llama (13b) | Université de Tokyo Izumi Lab | ? | |
| Llama 3 Suzume 8B (8B-japanese, 8B-japanese-gguf) |
Llama 3 (8b) | megagonlabs/instruction_ja, ShareGPT, undisclosed dataset | Lightblue | Llama 3 Community License (?)5 |
| ganchengguang/Yoko-7B-Japanese-v1 | Llama 2 (7b) | Université nationale de Yokohama Mori Lab | ? | |
| Sparticle/llama-2-7b-chat-japanese-lora | Llama 2 (7b) | Sparticle | ? | |
| izumi-lab/llama-7b-japanese-lora-v0-5ep | Llama (7b) | Université de Tokyo Izumi Lab | ? | |
| lightblue/jod | Mistral-7B-SlimOrca (7b) | Lightblue | Apache 2.0 | |
| NTQAI/chatntq-7b-jpntuned | RWKV-4 World (7b) | NTQ Solution | ? |
Spécifique à un domaine
| Domaine | Base du Model | Développeur | Licence | |
|---|---|---|---|---|
| JMedLoRA (llama2-jmedlora-6.89ep) |
Médecine | Llama 2 (70b) | Université de Tokyo - AI Group du Département hospitalier de médecine cardiovasculaire | CC BY-NC 4.0 |
Modèles fusionnés
| Modèles originaux (LLMs japonais en gras) | Développeur | Licence | |
|---|---|---|---|
| EvoLLM-JP-A (v1-7B) |
Shisa Gamma 7B (v1), Arithmo2 Mistral 7B, Abel 7B 002 | Sakana AI | Apache 2.0 |
| EvoLLM-JP (v1-7B, v1-10B) |
Shisa Gamma 7B (v1), WizardMath-7B-V1.1, Abel 7B 002 | Sakana AI | MICROSOFT RESEARCH LICENSE |
Modèles encodeur
D’usage général
| Architecture | Données d’entraînement | Développeur | Licence | HuggingFace? 6 | |
|---|---|---|---|---|---|
| KyotoUniBERT | BERT (base, large) | Wikipédia en japonais (18M articles) | Université de Kyoto Laboratoire de traitement des langues et des médias | Apache 2.0 | △ |
| TohokuUniversityBERT | BERT (base, large) | base (v1): Wikipédia en japonais (17M articles / 2.6GB) base (v2) & large: Wikipédia en japonais 4.0GB base (v3) & large (v2): Wikipédia en japonais (4.9GB), Japanese CC‑100 (74.3GB) |
Université de Tohoku - Groupe TAL | base (v1, v2) & large: CC BY‑SA 3.0 base (v3) & large (v2): Apache 2.0 |
◯ (base (v1), base (v1, char-level), base (v2), base (v2, char-level), large, large (char-level), base (v3), base (v3, char-level), large (v2), large (v2, char-level)) |
| NICT BERT | BERT (base) | Wikipédia en japonais | NICT | CC BY 4.0 | △ |
| colorfulscoop BERT | BERT (base) | Wikipédia en japonais | Colorful Scoop | CC BY‑SA 3.0 | ◯ |
| UniversityOfTokyoBERT | BERT (small) | Wikipédia en japonais (2.9GB) | Université de Tokyo Izumi Lab | CC BY‑SA 4.0 | ◯ |
| chiTra (Sudachi Transformers) | BERT (base) | NINJAL Web Japanese Corpus (148GB) | NINJAL & WAP Tokushima - Laboratoire IA et TAL | Apache 2.0 | △ |
| ACCMS BERT | BERT (base) | Wikipédia en japonais (3.3GB) | Université de Kyoto ACCMS | CC BY‑SA 4.0 | ◯ |
| HitachiBERT | BERT (base) | Wikipédia en japonais, Japanese CC‑100 | Hitachi | CC BY‑NC‑SA 4.0 | ◯7 |
| Bandai Namco DistilBERT | DistilBERT | (Distillation de BERT (base) de l’Université du Tohoku) | Bandai Namco Research | MIT | ◯ |
| LINE DistilBERT | DistilBERT | (Distillation de LINE en interne BERT model) | LINE | Apache 2.0 | ◯ |
| rinna RoBERTa | RoBERTa (base) | Wikipédia en japonais, Japanese CC‑100 | rinna | MIT | ◯ |
| WasedaRoBERTa | RoBERTa (base, large) | Wikipédia en japonais, Japanese CC‑100 | Waseda Kawahara Lab | CC BY‑SA 4.0 | ◯ (base, large, large (seq512))8 |
| InformatixRoBERTa | RoBERTa (base) | Wikipédia en japonais, Web Articles (25GB) |
Informatix | Apache 2.0 | △ |
| KyotoUniversityRoBERTa | RoBERTa (base, large) | Wikipédia en japonais, Japanese CC‑100 | Université de Kyoto Laboratoire de traitement des langues et des médias | CC BY‑SA 4.0 | ◯ (base (char-level), large (char-level)) |
| YokohamaNationalRoBERTa | RoBERTa (base) | Wikipédia en japonais (3.45GB) | Université nationale de Yokohama - Mori Lab | Apache 2.0 | ◯ |
| Megagon Labs RoBERTa | RoBERTa (base)9 | Japanese mC4 (200M sentences) | Megagon Labs (Recruit Holdings) |
MIT | ◯ |
| ACCMS RoBERTa | RoBERTa (base) | Wikipédia en japonais (3.3GB) + Japanese CC‑100 (70GB) | Université de Kyoto ACCMS | CC BY‑SA 4.0 | ◯ |
| CinnamonELECTRA | ELECTRA (small) | Wikipédia en japonais | Cinnamon | Apache 2.0 | ◯ |
| Megagon Labs ELECTRA | ELECTRA (base) | Japanese mC4 (200M sentences) | Megagon Labs (Recruit Holdings) |
MIT | ◯ |
| UniversityOfTokyoELECTRA | ELECTRA (small, base) | Wikipédia en japonais (2.9GB) | Université de Tokyo Izumi Lab | CC BY‑SA 4.0 | ◯ (small, base) |
| JapaneseRoFormer | RoFormer (base) | Wikipédia en japonais (3.45GB) | Université nationale de Yokohama - Mori Lab | Apache 2.0 | ◯ |
| JapaneseLUKE | LUKE (base, large) | Wikipédia en japonais | Studio Ousia | Apache 2.0 | ◯ (base, large) |
| KyotoUniversityDeBERTaV2 | DeBERTaV2 (tiny, base, large) | Wikipédia en japonais, Japanese CC‑100, Japanese OSCAR (171GB) |
Université de Kyoto - Laboratoire du traitement des langues et médias | CC BY‑SA 4.0 | ◯ (tiny, tiny (char-level), base, large) |
| UniversityOfTokyoDeBERTaV2 | DeBERTaV2 (small, base) | Wikipédia en japonais, Japanese Wikinews, Japanese CC-100, Japanese mC4, Japanese OSCAR | University of Tokyo Izumi Lab | CC BY-SA 4.0 | ◯ (small, base) |
| JapaneseBigBird | BigBird (base) | Wikipédia en japonais, Japanese CC‑100, Japanese OSCAR | Waseda Kawahara Lab | CC BY‑SA 4.0 | ◯ |
| JapaneseLayoutLM | LayoutLM (base) | Pre-trained on Japanese Wikipedia, initialized with TohokuUniversityBERT | The Japan Research Institute, Limited | CC BY-SA 3.0 | ◯ |
Spécifique à un domaine
| Architecture | Données d’entraînement | Développeur | Licence | HuggingFace? | |
|---|---|---|---|---|---|
| JapaneseNewsBERT | BERT (base) | Articles sur l’économie en japonais(3M articles) | Stockmark | CC BY 4.0 | △ |
| JapaneseNewsXLNet | XLNet (base) | Articles sur l’économie en japonais (3M articles) | Stockmark | ? | ◯ ※ Version non officielle |
| JapaneseNewsALBERT | ALBERT (base) | Articles sur l’économie en japonais (3M articles) | Stockmark | ? | △ |
| Laboro BERT | BERT (base, large) | Corpus web en japonais (Actualités, blogs, etc) (12GB) |
Laboro.AI | CC BY‑NC 4.0 | ✕ |
| Laboro DistilBERT | DistilBERT | (Distillation of Laboro BERT(base)) | Laboro.AI | CC BY‑NC 4.0 | ◯ |
| JapaneseBlogELECTRA | ELECTRA (small) | Corpus de blogs en japonais (354M sentences) | Université de technologie de Kitami - Laboratoire de Masui-Ptaszynski | CC BY‑SA 4.0 | ◯ |
| JapaneseSpokenLanguageBERT | BERT (base) | Formation supplémentaire pour TohokuUniversityBERT en utilisant le Corpus of Spontaneous Japanese (CSJ) (Dans le modèle DAPT, le compte rendu de la diète est également utilisé) |
Retrieva | Apache 2.0 | ◯ |
| JapaneseFinancialBERT | BERT (small, base)10 | Wikipédia en japonais, Japanese Financial Corpus (27M sentences/5.2GB) | Université de Tokyo Izumi Lab | CC BY‑SA 4.0 | ◯ (small, base) |
| JapaneseFinancialELECTRA | ELECTRA (small) | Wikipédia en japonais (20M sentences/2.9GB), Japanese Financial Corpus (27M sentences/5.2GB) | Université de Tokyo Izumi Lab | CC BY‑SA 4.0 | ◯ |
| UTH-BERT | BERT (base) | Dossiers médicaux en japonais (120M lignes) | Université de Tokyo Hôpital Cours de développement en IA pour la médecine |
CC BY‑NC‑SA 4.0 | △ |
| medBERTjp | BERT (base) | Wikipédia en japonais, Corpus médical en japonais (“今日の診療プレミアム/Today’s Care Premium” Web Version) | Université d’Osaka Hôpital Laboratoire d’information médicale |
CC BY‑NC‑SA 4.0 | △ |
| JMedRoBERTa | RoBERTa (base) | Japanese Medical Papers (11M sentences/1.8GB) | Université de Tokyo Aizawa Lab | CC BY‑NC‑SA 4.0 | ◯ (ManbyoWordPiece, SentencePiece)11 |
| AcademicRoBERTa | RoBERTa (base) | CiNii Japanese Papers (6.3M sentences) | Université d’Ehime Laboratoire IA | Apache 2.0 | ◯ |
Plongement lexical par mots et par documents
Modèles Vision-Language
Text+Image vers Text
D’usage général
| Architecture | Données d’entraînement | Développeur | Licence | |
|---|---|---|---|---|
| EvoVLM-JP (v1-7B) |
- | - (merged from Shisa Gamma 7B (v1) and LLaVA-1.6-Mistral-7B) | Sakana AI | Apache 2.0 |
| Heron (blip-ja-stablelm-base-7b-v0, blip-ja-stablelm-base-7b-v1, blip-ja-stablelm-base-7b-v1-llava-620k, git-ja-stablelm-base-7b-v0, git-ELYZA-fast-7b-v0, git-ja-stablelm-base-7b-v1) |
BLIP-2 / GIT | v1: LLaVA-Instruct-150K-JA or LLaVA-Instruct-620K-JA v0: LLaVA-Instruct-150K-JA, Japanese STAIR Captions, Japanese Visual Genome VQA dataset |
Turing | CC BY-NC 4.0 |
| Japanese Stable VLM (japanese-stable-vlm) |
LLaVA-1.5 | Japanese CC12M, STAIR Captions, jeu de données Japanese Visual Genome VQA | Stability AI | STABILITY AI JAPANESE STABLE VLM COMMUNITY LICENSE |
| Japanese InstructBLIP Alpha (japanese-instructblip-alpha) |
InstructBLIP | Japanese CC12M, STAIR Captions, jeu de données Japanese Visual Genome VQA | Stability AI | JAPANESE STABLELM RESEARCH LICENSE |
| rinna MiniGPT-4 (bilingual-gpt-neox-4b-minigpt4) |
MiniGPT-4 | CC12M, COCO 2014, Visual Genome, STAIR Captions, Japanese Visual Genome VQA dataset | rinna | MIT |
Spécifique à un domaine
| Domaine | Base du Model | Développeur | Licence | |
|---|---|---|---|---|
| watashiha/Watashiha-Llama-2-13B-Ogiri-sft-vlm | LLaVA | Oogiri | Watashiha | Llama 2 Community License |
Autres
| Architecture | Données d’entraînement | Développeur | Licence | |
|---|---|---|---|---|
| Recruit CLIP (japanese-clip-vit-b-32-roberta-base) |
CLIP | environ 120 millions de légendes de laion2B-multi | Recruit Holdings | CC BY-4.0 |
| Japanese Stable CLIP (japanese-stable-clip-vit-l-16) |
SigLIP | CC12M traduit en japonais, STAIR Captions | Stability AI | STABILITY AI JAPANESE STABLE CLIP COMMUNITY LICENSE |
| rinna CLIP (japanese-clip-vit-b-16) |
CLIP | CC12M traduit en japonais | rinna | Apache 2.0 |
| rinna CLOOB (japanese-cloob-vit-b-16) |
CLOOB | CC12M traduit en japonais | rinna | Apache 2.0 |
| HAKUHODO Technologies CLIP (base, deeper, wider) |
CLIP | about 120 million captions from laion2B-multi | HAKUHODO Technologies | CC BY-NC-SA 4.0 |
Text vers Image
| Architecture | Training Data | Developer | License | |
|---|---|---|---|---|
| EvoSDXL-JP (v1) |
- | - (merged from several diffusion models, including Japanese Stable Diffusion XL) | Sakana AI | Apache 2.012 |
| Japanese Stable Diffusion XL (japanese-stable-diffusion-xl) |
Stable Diffusion | Inconnu | Stability AI | STABILITY AI JAPANESE STABLE DIFFUSION XL COMMUNITY LICENSE |
| TohokuUniversity Stable Diffusion (base, refiner) |
Stable Diffusion | Corpus parallèle anglais-japonais de la tâche partagée WMT2023, environ 13 millions de légendes de laion2B-multi | Université de Tohoku - Groupe TAL | CreativeML OpenRAIL-M License |
| rinna Stable Diffusion (japanese-stable-diffusion) |
Stable Diffusion | LAION-5B Japanese Subset (100M images) | rinna | CreativeML OpenRAIL-M License |
Modèles Speech-Language
Reconnaissance automatique de la parole
| Architecture | Données d’entraînement | Développeur | Licence | |
|---|---|---|---|---|
| Kotoba-Whisper (v1.0, v1.0-ggml) |
Distil-Whisper | ReazonSpeech | Kotoba Technologies | Apache 2.0 |
| Nue ASR (nue-asr) |
Nue ASR (HuBERT + LLM) |
ReazonSpeech | rinna | Apache 2.0 |
| ReazonSpeech (espnet-v1, espnet-next, espnet-v2, nemo-v2) |
ESPnet (Conformer-Transducer) / NeMo (FastConformer-RNNT) | ReazonSpeech | Reazon Holdings | Apache 2.0 |
Autres
| Architecture | Données d’entraînement | Développeur | Licence | |
|---|---|---|---|---|
| Kotoba-Speech (v0.1) |
Transformer | undisclosed | Kotoba Technologies | Apache 2.0 |
| UniversityOfTokyoHuBERT (base-jtube) |
HuBERT | JTubeSpeech | University of Tokyo Saruwatari & Takamichi Lab |
MIT |
| rinna HuBERT (base, large) |
HuBERT | ReazonSpeech | rinna | Apache 2.0 |
Standard d’évaluation pour les LLM en japonais
Benchmarks hybrides
Nejumi LLM Leaderboard Neo (Weights & Biases)
Cela compile les résultats d’une évaluation complète par llm-jp-eval, qui évalue la compréhension de la langue dans un format de questions-réponses, et Japanese MT-bench, qui évalue la capacité générative dans un contexte d’invites de dialogue.
Référence traditionnelle basé sur des tâches de Compréhension du langage naturel (NLU)
llm-jp-eval (LLM-jp)
Un outil qui évalue automatiquement les LLM japonais à travers plusieurs jeux de données.
La liste complète des jeux de données pris en charge peut être trouvée ici (qui comprend également des tâches telles que JNLI et JCommonsenseQA de JGLUE).
Les résultats de l’évaluation sont compilés sur le classement llm-jp-eval.
JP Language Model Evaluation Harness (Stability AI)
Un fork par Stability AI de EleutherAI/lm-evaluation-harness. Il s’agit d’un outil pour évaluer automatiquement les LLM japonais à travers plusieurs jeux de données.
La liste complète des jeux de données pris en charge peut être trouvée ici (qui comprend également des tâches telles que JNLI et JCommonsenseQA de JGLUE).
Il y a un résumé détaillé des résultats de l’évaluation par rinna : [rinna] Benchmark de Stability-AI/lm-evaluation-harness
JGLUE (Université de Waseda Laboratoire Kawahara et Yahoo)
Version japonais de GLUE référence suite, avec les tâches MARC-ja, JCoLA, JSTS, JNLI, JSQuAD, et JCommonsenseQA. JCoLA vient du laboratoire d’Oseki de l’université de Tokyo. Voir ici and here (ja only) pour plus d’informations sur chaque tâches.
JMMLU (Université de Waseda Laboratoire Kawahara)
Un benchmark construit comme une version japonaise du MMLU Benchmark, consistant en des questions à choix multiples de divers domaines académiques, y compris les sciences naturelles, les humanités et les sciences sociales. En plus de la traduction du MMLU original, il contient de nouveaux problèmes basés sur le contexte culturel unique du Japon (problèmes spécifiques au Japon).
Japanese Open LLM Leaderboard (LLM-jp)
Semblable à Open LLM Leaderboard de Huggingface, ce classement fournit une vérification sur les LLM japonais. Vous pouvez vérifier la performance des LLM japonais dans des tâches en anglais.
Standard des tâches génératives ouvertes
Japanese MT-bench (Stability AI)
Version japonaise du MT-bench qui interroge sur la capacité à converser en plusieurs tournures. Il inclut 80 questions, 10 de chacune des 8 catégories : écriture, jeu de rôle, raisonnement, maths, codage, extraction, STEM, sciences humaines. Certaines questions ont été modifiées pour s’adapter à la culture japonaise lors de la création de la version japonaise. Il comprend également un script qui réalise une évaluation absolue en 10 niveaux par GPT-4.
Rakuda Benchmark (YuzuAI)
Classement basé sur les réponses des modèles avec 40 questions ouvertes la géographie, l’histoire, la politique, et la société japonaise. Utilise GPT-4 pour évaluer les résultats du modèle par paires, puis classe les modèles en ajustant le maximum de vraisemblance sur le modèle de probabilité d’Elo/Bradley-Terry avec les préférences de GPT-4. Voir ici pour les données et le code utilisé afin de générer le classement ici pour obtenir davantage d’explications.
ELYZA-tasks-100 (ELYZA)
Classement basé sur les réponses des modèles avec 100 tâches complexes et diverses, y compris les tâches testant la synthèse, la correction, l’abstraction, l’induction et d’autres compétences. Utilise des humains pour noter les réponses du modèle, puis classe les modèles en fonction de leurs scores moyens. Les résultats d’évaluation peuvent être trouvés ici et ici. Pour une évaluation incluant les modèles plus récents, voir ici.
Japanese Vicuna QA Benchmark (Université de Kyoto Laboratoire de traitement des langues et des médias)
Il s’agit de la version japonaise de vicuna-blog-eval, qui est le précurseur de MT-Bench. Il comprend 80 questions sur la connaissance générale, le jeu de rôle, le bon sens, l’estimation de Fermi, la pensée contrefactuelle, le codage, les mathématiques, et l’écriture. Il comprend également un script pour une évaluation automatique par GPT-4 (calcul du taux de victoire). Le tableau de classement peut être trouvé ici.
Benchmarks pour mesurer les capacités de raisonnement logique
JFLD (Japanese Formal Logic Deduction) (Hitachi)
Un dataset pour évaluer les capacités de raisonnement déductif des LLM japonais (la version japonaise de la FLD (Formal Logic Deduction) proposée par les mêmes auteurs). Il se caractérise par le fait qu’il est composé d’exemples contrefactuels pour évaluer indépendamment des connaissances que possède le LLM.
JHumanEval (Université des Femmes du Japon - Laboratoire Kuramitsu)
Une version japonaise du benchmark HumanEval, qui évalue la capacité à générer du code Python à partir d’instructions en anglais. En créant la version japonaise, le texte a d’abord été traduit automatiquement, puis corrigé manuellement.
Benchmarks pour mesurer la performance dans des domaines spécifiques
Japanese Language Model Financial Evaluation Harness (Preferred Networks)
Un benchmark pour les LLM japonais dans le secteur financier. Il comprend des tâches telles que l’analyse des sentiments dans la finance (chabsa), des tâches de connaissances de base en analyse de titres (cma_basics), des tâches relatives aux audits dans les examens de comptable public certifié (cpa_audit), des tâches à questions à choix multiple dans les examens de planificateur financier (fp2), et des tâches d’examen blanc pour les examens de vendeurs de titres (security_sales_1). Pour plus de détails, veuillez consulter ici.
Stockmark Business Questions (Stockmark)
La collection comprend 50 questions qui approfondissent les connaissances sur des sujets tels que les tendances du marché, l’actualité, les problèmes sociaux et les tendances commerciales.
Benchmarks pour modèles d’embeddings
JMTEB (SB Intuitions)
Un benchmark développé comme la version japonaise de MTEB. Il se compose de tâches telles que le regroupement de documents, la classification de textes, la similarité de phrases, la prédiction d’étiquetage de paires de phrases et l’extraction de texte (une tâche de reclassement a été récemment ajoutée).
Benchmarks pour modèles vision-langage
Heron-Bench (Turing)
21 images se voient attribuer un total de 102 questions. Il est caractérisé par des paires image-question qui nécessitent une connaissance liée au Japon.
JA-VLM-Bench-In-the-Wild (Sakana AI)
Un jeu de données préparé indépendamment par Sakana AI pour évaluer EvoVLM-JP-v1-7B. Il se compose de 50 questions attribuées à 42 images. Il se caractérise par des images et des questions qui exigent une connaissance du Japon.
LLaVA-Bench-In-the-Wild (Japanese) (Turing)
Ceci est la version japonaise de LLaVA-Bench-In-the-Wild, traduite à l’aide de DeepL. Il se compose de 60 questions attribuées à 24 images.
LLaVA-Bench (COCO) Japonais (Turing)
Il s’agit de la version japonaise, traduite par DeepL, du jeu de données LLaVA-Bench (COCO) utilisé pour évaluer LLaVA. Il se compose de 30 images, chacune avec 3 types de questions qui leur sont attribuées.
Références pour les modèles et les architectures
Références pour les méthodes d’entraînement
| Model/Architecture | Date | Meeting/Journal | Paper |
|---|---|---|---|
| PPO (RLHF) | 2017.07.20 | - | Proximal Policy Optimization Algorithms |
| Instruction Tuning (Supervised Fine-tuning; SFT) |
2021.09.03 | ICLR 2022 | Finetuned Language Models Are Zero-Shot Learners |
| DPO | 2023.05.29 | NeurIPS 2023 | Direct Preference Optimization: Your Language Model is Secretly a Reward Model |
| SteerLM | 2023.10.09 | Findings of EMNLP 2023 | SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF |
Nos contributeurs
Nous aimons les contributeurs ! N’hésitez pas à contribuer à ce projet.

Citation
La synthèse de ce répertoire est également publiée sous forme de prépublication: Exploring Open Large Language Models for the Japanese Language: A Practical Guide
Lorsque vous référencez ce répertoire, veuillez le citer comme suit:
@article{awesomeJapanese2024,
title={{Exploring Open Large Language Models for the Japanese Language: A Practical Guide}},
author={Kaito Sugimoto},
doi={10.51094/jxiv.682},
journal={Jxiv preprint},
year={2024}
}
-
Certaines améliorations de performances ont été apportées au modèle Llama original. Voir ici pour plus détails. ↩
-
Les détails n’ont pas été rendus publics, mais l’ensemble de données privé comprend des jeux de données de l’équipe japonaise du projet EleutherAI Polyglot et des membres de Stable Community Japan. ↩
-
Ce projet a mené des recherches d’évaluation sur l’utilisation de la génération de droite à gauche au lieu de la génération habituelle de gauche à droite, en publiant des modèles de gauche à droite et de droite à gauche. ↩
-
Cependant, si une utilisation commerciale de KARAKURI LM est souhaitée, un contact direct avec le développeur, KARAKURI Inc., est requis. ↩
-
Dans l’ajustement des instructions, comme il utilise des données générées par les modèles d’OpenAI, tels que GPT-3.5, GPT-4, etc. pour l’entraînement, il se peut qu’il viole les termes d’OpenAI. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
-
○: Le modèle se trouve sur le Model Hub d’HuggingFace et peut être chargé avec la commande
AutoModel.from_pretrained(). △: Le modèle ne se trouve pas sur le Model Hub mais peut être chargé manuellement avec la bibliothèque de transformateurs HuggingFace. ✕: Le modèle ne se charge pas avec HuggingFace. ↩ -
Ce projet a mené des recherches d’évaluation sur l’analyse morphologique avant la tokenisation et a publié son modèle le plus performant, qui utilisait Juman++ et BPE. ↩
-
nlp-waseda/roberta-base-japanese et nlp-waseda/roberta-large-japanese entrainé avec une longueur de context 128 token, mais nlp-waseda/roberta-large-japanese-seq512 étendu la longueur du contexte à 512. ↩
-
Étendu la longueur du contexte de 128 à 512. ↩
-
Le modèle “Small” s’entraîne sur Wikipédia japonais et le Corpus financier japonais simultanément, tandis que le modèle “Base” prend le TohokuUniversityBERT et dispense un apprentissage supplémentaire sur le Corpus financier japonais. ↩
-
ManbyoWordPiece lance une étape de prétokenization en utilisant MeCab (IPA+Manbyo dictionaries), puis utilise WordPiece pour la tokenization sous-mots, pendant que le modèle SentencePiece segmente le texte directement en utilisant un modèle unigram. ↩
-
Cependant, il appelle à la réflexion pour l’utilisation dans la recherche et l’éducation. De plus, soyez conscient que certaines des licences pour les modèles sources ne sont pas Apache 2.0. ↩